
四、創建資料集
1. 設定資料集
於左側欄位點選「Annotate」,在右側畫面中會顯示標註與尚未標註的資訊。
點選中間名為「ANNOTATING」已被標註的照片群區塊。
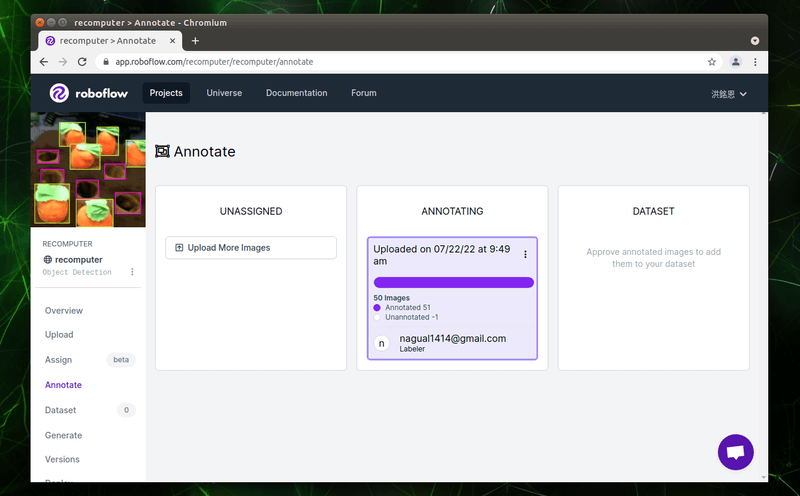
在此檢查每張照片是否有遺漏標註的部份,確認完畢後請點選右上角的「Add images to Dataset」按鈕。
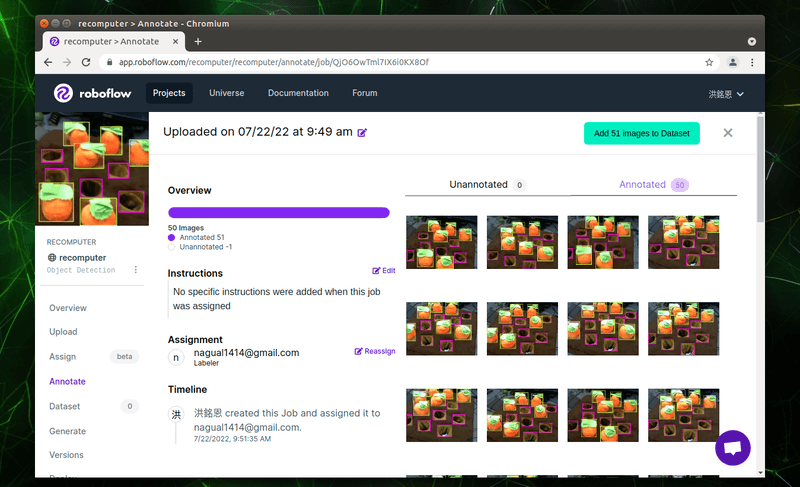
資料集的部份通常會分群為「Train」、「Valid」與「Test」,用於訓練模型與測試模型使用。彼此之間的比例,大家可以拖拉兩個「空心的圓圈」做調整。調整完畢請點選「Add Images」。
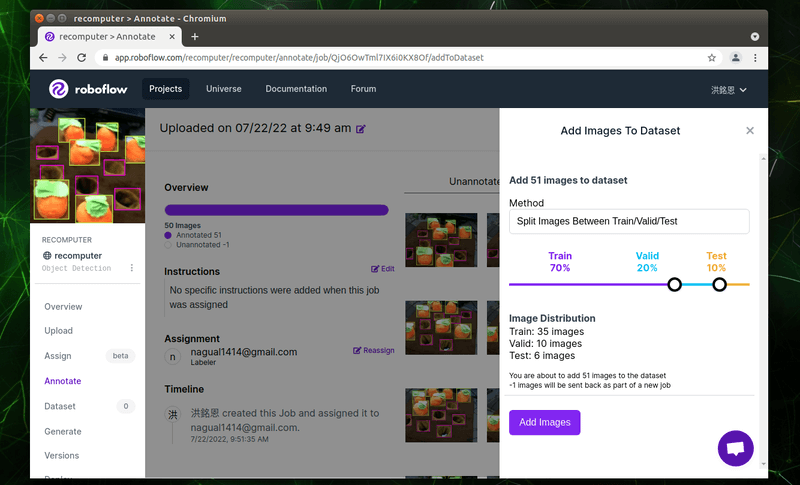
2. 擴增資料集
完成資料的分群之後,我們可以依照現有的照片做一些變化,擴充照片的數量。
第三項的「Preprocessing」可以快速地幫我們的照片做一些預處理,例如調整照片的大小,筆者在此保留預設值,並按下「Continue」。
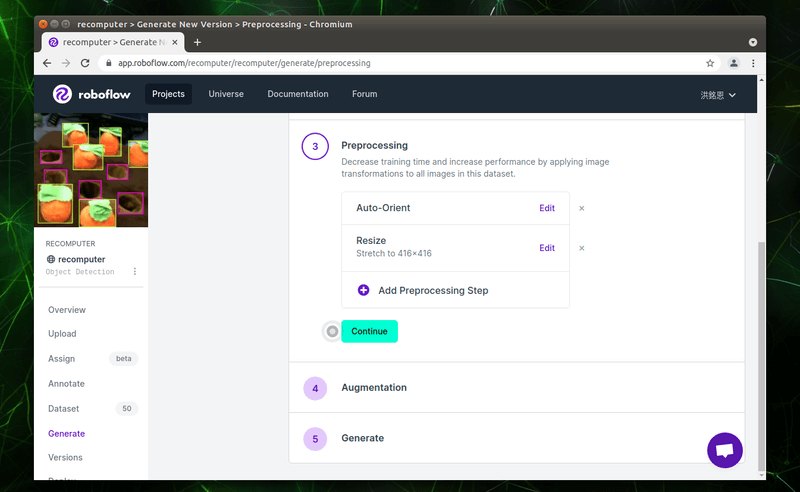
第四項的「Augmentation」可以幫助我們增強數據,請點選「Add Augmentation Step」,選取我們想要增強的效果。
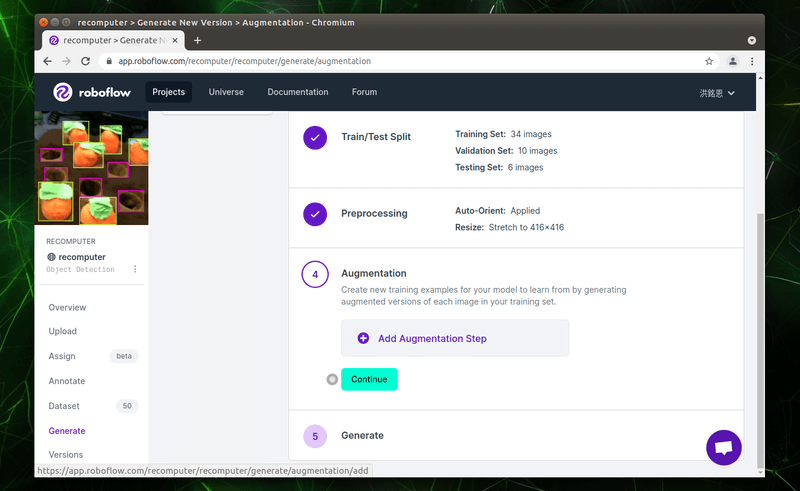
畫面中可以看到,有不少增強我們照片的效果,大家可以點來看看,並選擇是否使用。
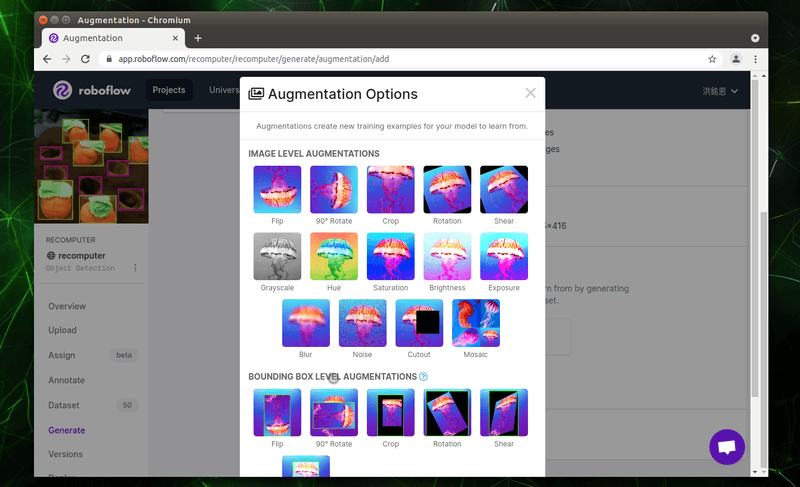
比方說我選擇了「Hue」,可以看到這個效果能隨機變換照片的顏色,變化的幅度也能自行調整。若確認要使用該效果,可以點選「Apply」按鈕。
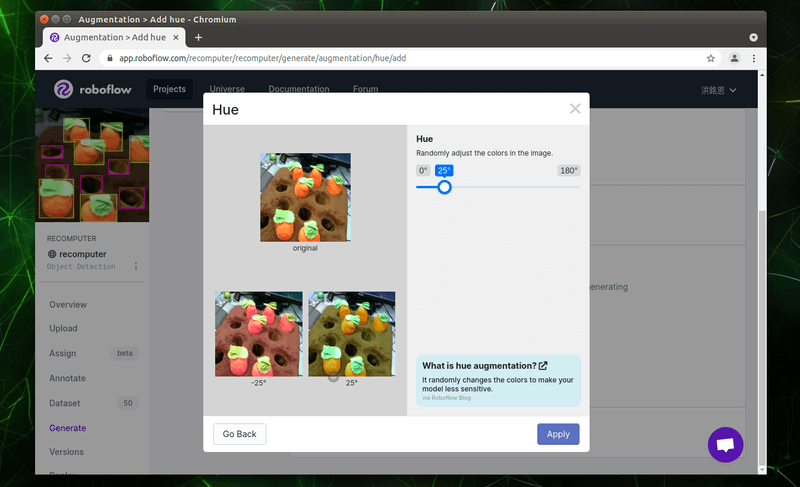
依照方才的操作,筆者共選擇了五種增強的效果,如下圖所示,請按下「Continue」按鈕繼續。
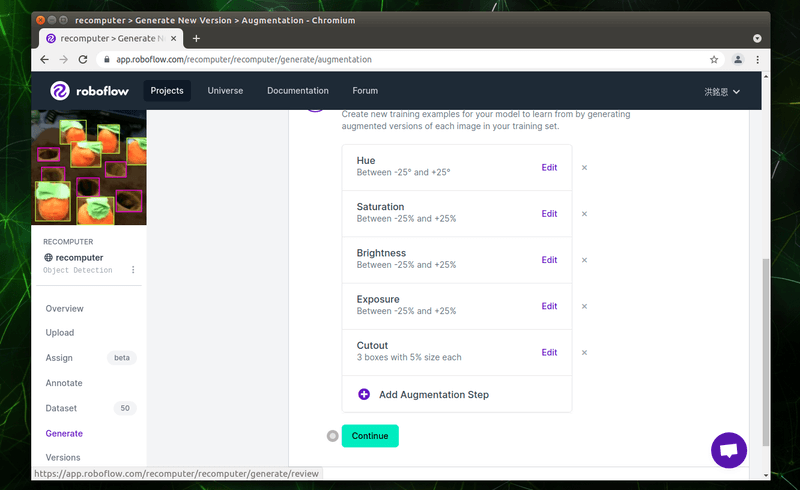
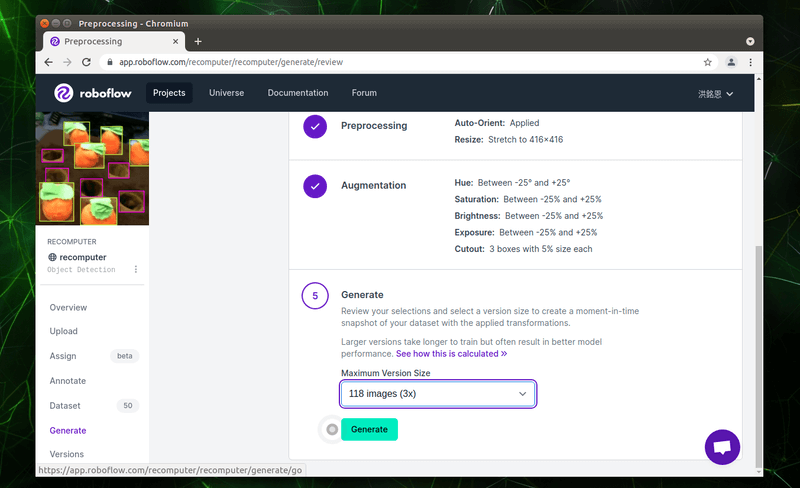
最後我們可以選擇透過上述的增強效果組合,我們要擴充到多少張照片,免費的用戶可以擴充到三倍,在此選擇三倍的選項並按下「Generate」產生增強後的資料集。
3. 導出資料集
完成資料集的創建後,我們就能匯出資料集,以便用於後續的訓練。
請點選畫面中的「Export」按鈕。
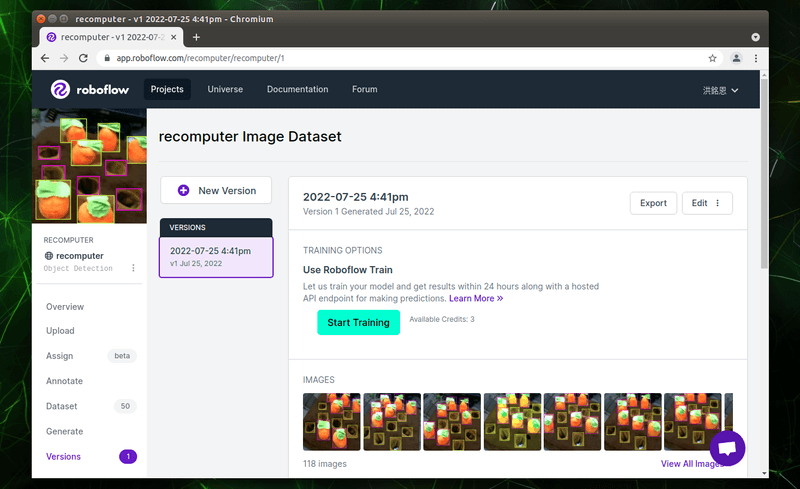
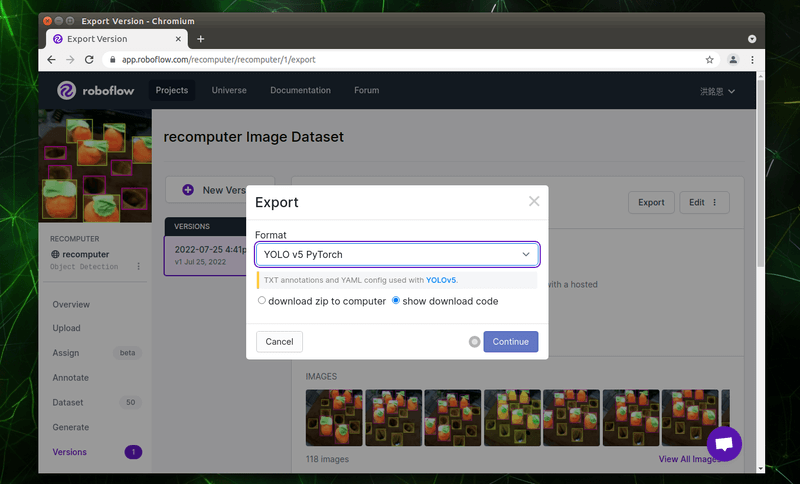
不同的模型,輸入的資料格式也會不同,請對應要訓練的模型,選擇正確的模型格式,我們要訓練的是 YOLOv5 模型,所以選擇「YOLOv5 PyTorch」。匯出的方式請選擇「show download code」,這樣待會兒能直接填入 Colab 中。
請按下「Continue」按鈕產生 code。
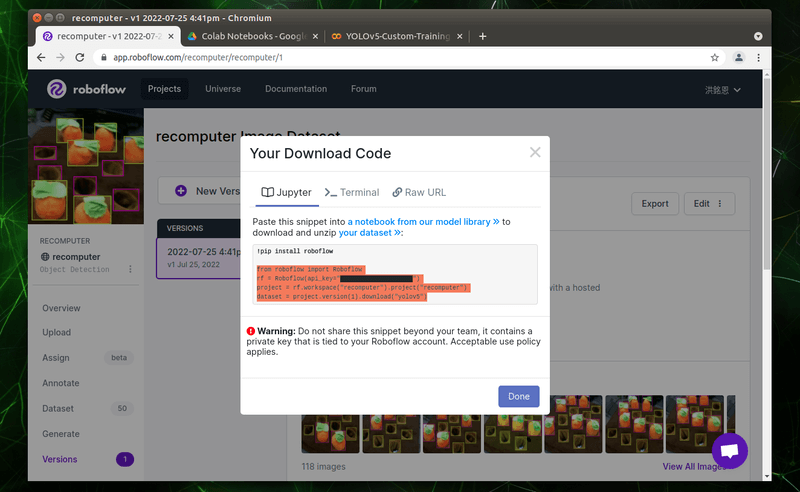
產生出來的 code 如下圖所示,圖中「api_key」的部份雖然是反黑的,但實際框選並複製貼上後就會顯示。
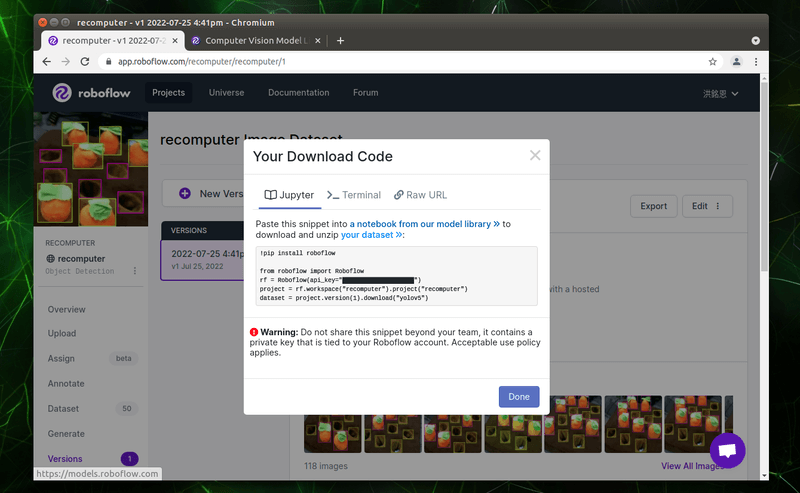
請大家將自己的「Download Code」如下圖一樣複製起來保留備用。
五、訓練模型
我們將使用「Google Colab」來訓練我們的模型,請大家自行開通 Google Drive 的 Colab 功能,在此就不贅述了。我們使用的程式碼是更改至官方 YOLOv5 提供的 Colab 程式碼,調整成方便大家使用並下載模型的方式。
程式碼連結如下:
https://colab.research.google.com/drive/1g5K7OQkrMCSvsT8dKqXw1Fou2aMF76YR?usp=sharing
點選網址後,建議按下複製的按鈕「Copy to Drive」,將程式碼複製到自己的 Google Drive。
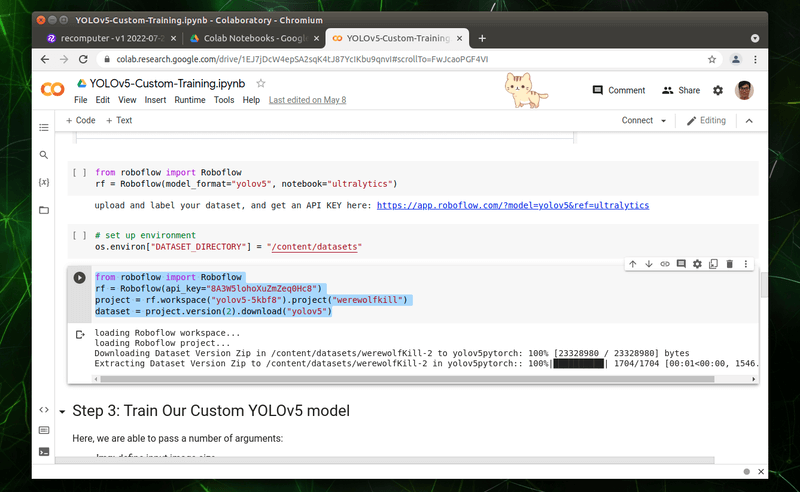
1. 修改資料集來源
首先將剛剛複製下來的「Download Code」,覆蓋如下圖所示的位置,取代成自己的資料集。
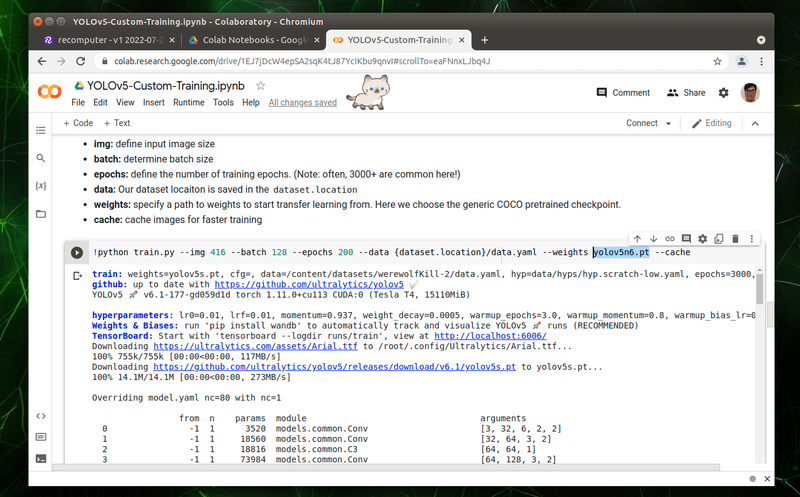
2. 修正訓練的參數
請找到如下圖所示的位置,將「–epochs」後方的數字更改為自己想要訓練的次數,筆者在此設定為 200,然後在「–weights」後方的模型設置,修改為「yolov5n6.pt」。
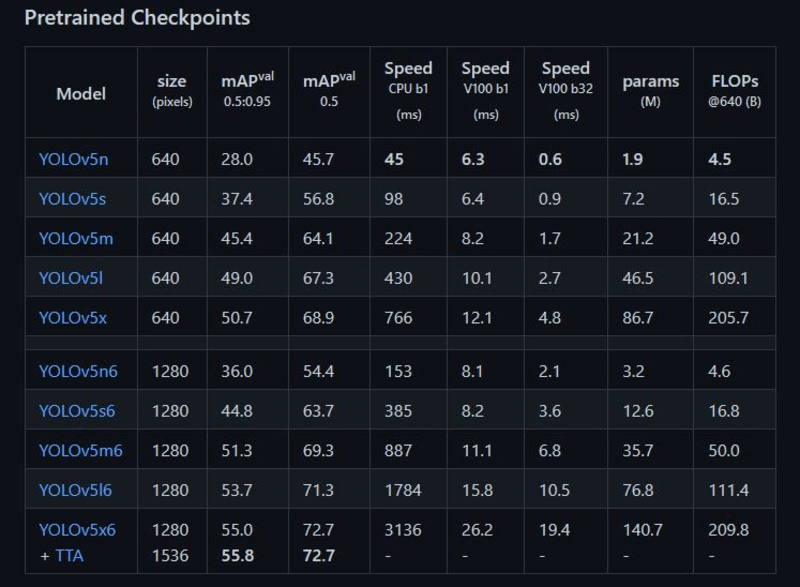
有關 YOLOv5 的模型選擇,可以參考 YOLOv5 官方的圖表。
3. 開始訓練模型
訓練的方式很簡單,直接讓每個框格內的程式碼依序 RUN 起來即可。但在執行前我們需要先設置使用的硬體。
請點選上方列表的「Runtime」並選擇選單內的「Change runtime type」。
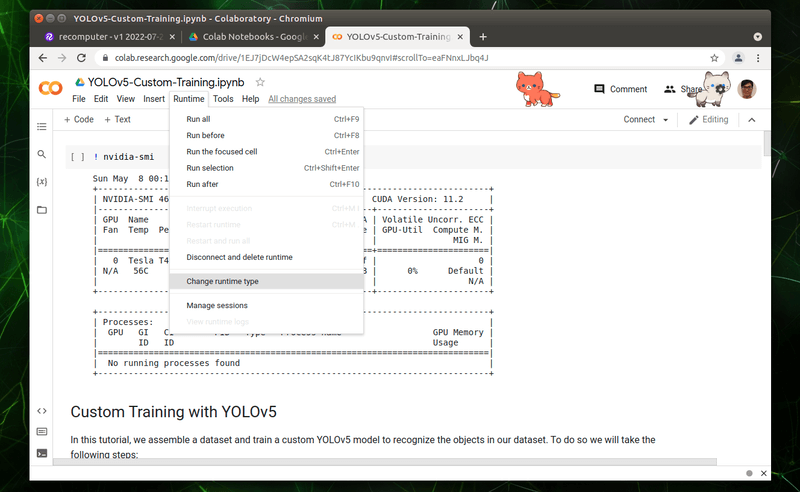
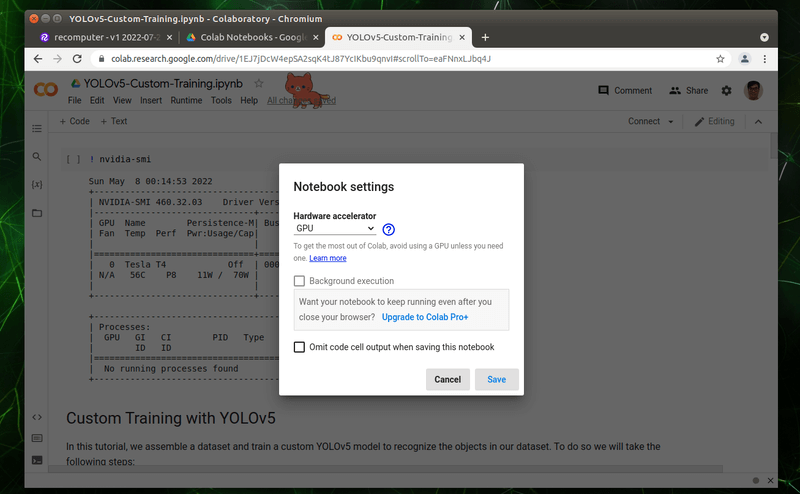
確認選取的硬體加速器是「GPU」,再按下儲存的按鈕。
接著按下右側有個「Connect」按鈕,連接 Google 免費提供給使用者的硬體。
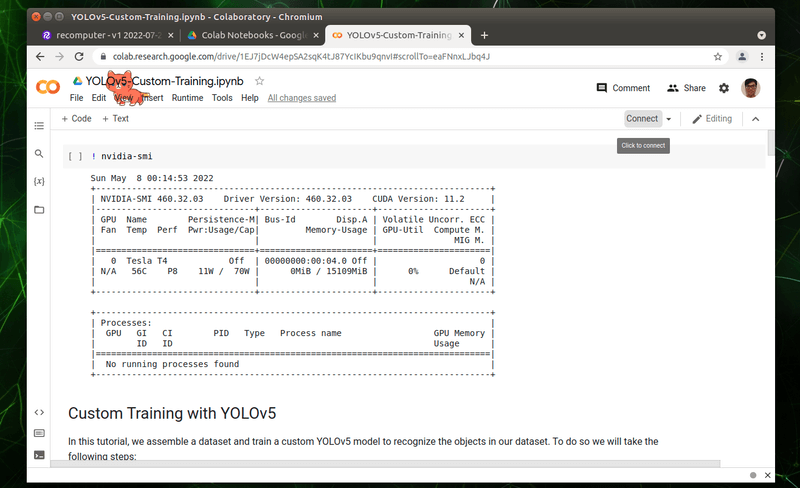
過程需要一段時間讓系統幫我們配置,完成後按鈕會變更為「Connecting」。看到這個字樣後,表示已經可以開始跑我們的程式了。
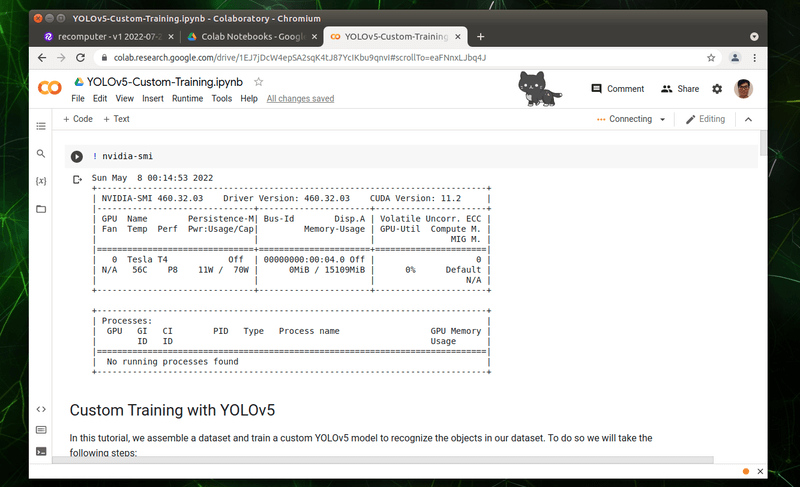
接下來同樣點選「Runtime」,並選擇「Run all」,這個選項會自動幫我們依序執行所有的程式碼。
執行完成的程式碼會如下圖所示,前頭除了有執行的順序編號之外,還會有綠色的打勾圖樣。執行完全部的程式碼後,網頁會自動下載訓練過程中最好的模型,並命名為「best.pt」。
六、結語
歷經千辛萬苦,大家是不是已經獲得了自己的 best.pt 呢?筆者認為過程中最艱辛的部份,大概就是最耗眼力與耐心的照片標註過程了,標註的好或不好都會直接影響最終的效果。這次介紹的 Roboflow 相當方便,特別是資料增強的部分相當方便與省事,其實還有很多功能,有興趣的話可以詳細查看官方網站的說明。
這篇文章所使用的照片量是五十幾張,但這只是為了示範與節省時間,實際上還是給多一點照片比較好,大家可以多做實驗,就能明白資料量與標註正確性的重要。
下一篇文章,將教大家如何使用自己訓練好的模型做推論,並徹底發揮使用 NVIDIA 系列產品的優勢,進一步加速推論的速度。不要錯過接下來精彩的內容,我們下篇文章見!



