

閱讀完「Jetson Nano DLI 教學(一):環境準備與 hello Camera」後,相信大家應該都已經對 NVIDIA DLI (Deep Learning Institute)有一定的認識了,本篇文章將在 JupyterLab 使用互動式介面實作影像分類模型的資料收集(data Collect)、訓練(Train)與預測(Predict)。
一、開啟影像分類 ipynb 筆記本
和 Jetson Nano DLI 教學(一) 相同的方式啟動 DLI docker image 並且完成登錄,從 JupyerLab 網頁介面左側檔案瀏覽器進去 Classification 目錄,開啟 classification_interactive.ipynb 檔案。
第一個段落相機 Camera 會開啟你的 USB Webcam 或 CSI 相機,預設是使用 USB 介面,如果開發者的環境是使用 CSI 介面的須修改程式碼把原始 USB 相機啟動程式碼註解,並取消註解 CSI 相機的啟動,如下:
# for USB Camera (Logitech C270 webcam), uncomment the following line
# camera = USBCamera(width=224, height=224, capture_device=0) # confirm the capture_device number
# for CSI Camera (Raspberry Pi Camera Module V2), uncomment the following line
camera = CSICamera(width=224, height=224, capture_device=0) # confirm the capture_device number二、以終為始,先看結果!
以筆者的經驗建議所有入門者先看到結果,有過體驗大概知道什麼是深度學習之後再回頭去看程式碼細節,學習效果會比較好。因此這邊會讓各位先玩互動式模型訓練與評估,程式碼細節稍後再做說明。就先讓我們依序執行所有程式碼 cell 段落,直到「顯示互動式工具!」 這段落完成就會看到一個如筆記本上說明的互動式介面:
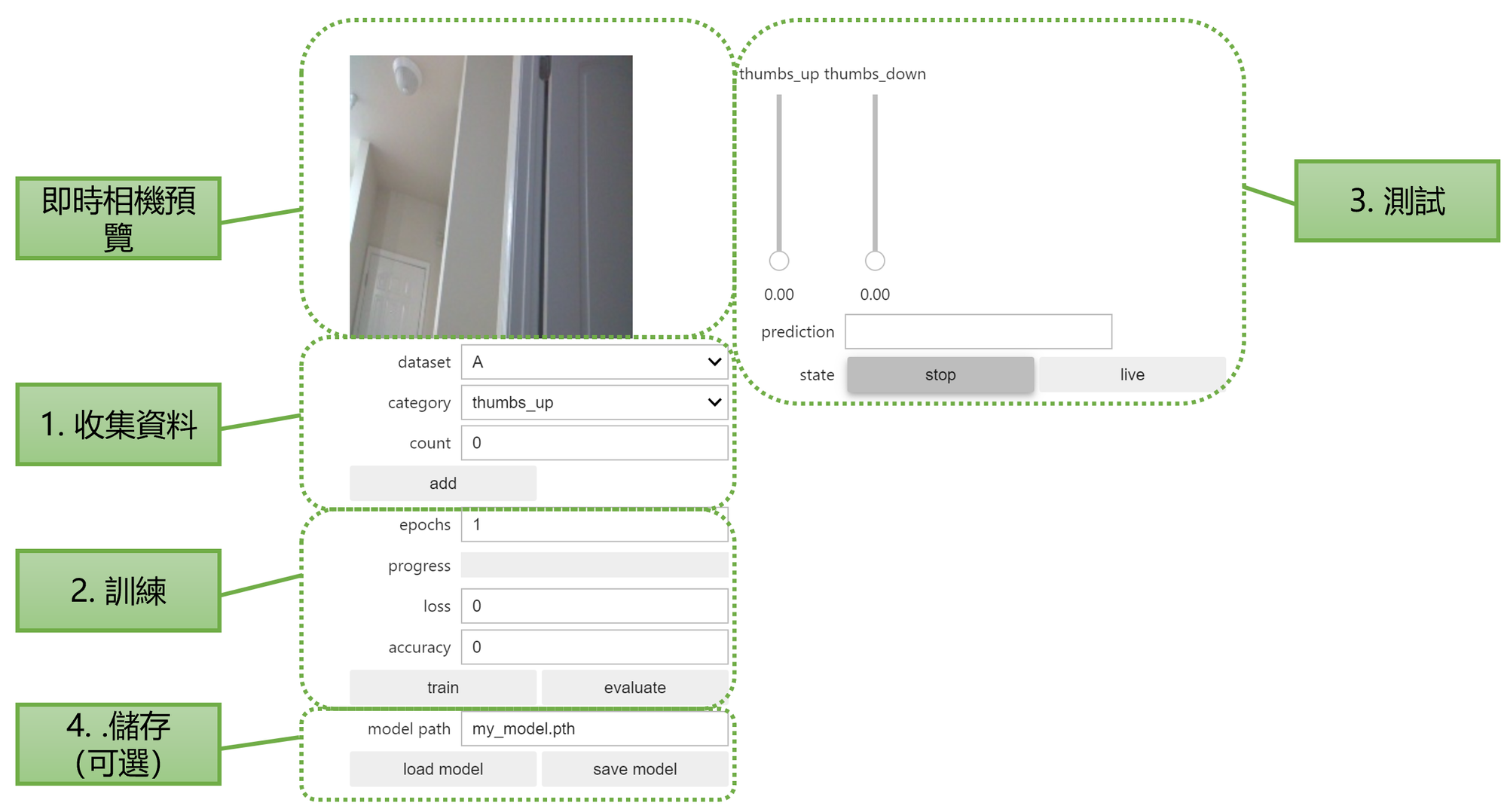
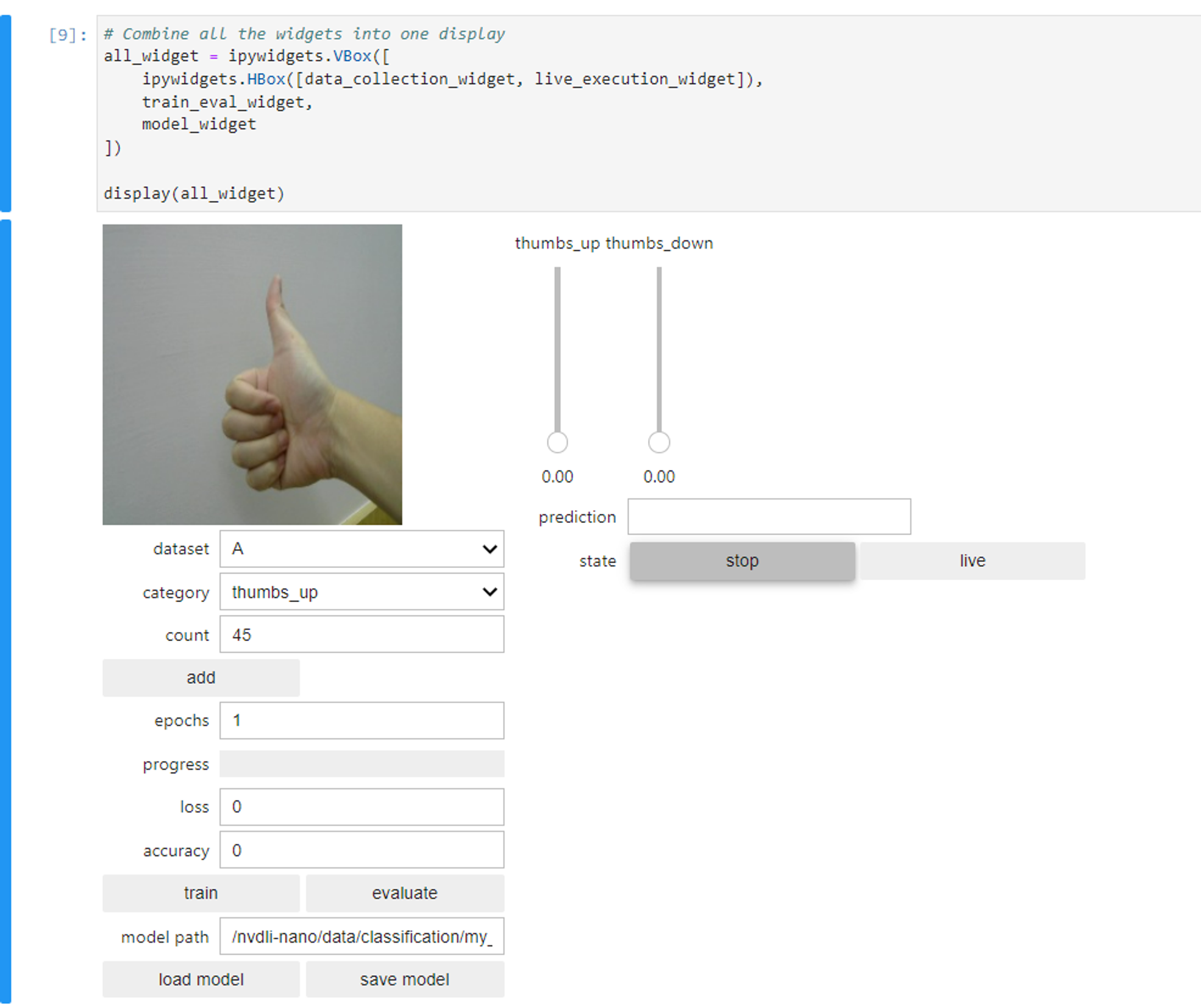
1. 收集資料
這裡看到資料集 dataset 可藉由下拉式選單選擇 A 或 B,這會有兩組不同的資料集,彼此分開儲存不共用,並且會實際寫入到檔案系統中。類別 category 則是影像分類的結果總共有哪幾類,在預設的範例中是一個二元分類,分別為 thumbs_up 與 thumbs_down,也就是讓我們做 讚 與 倒讚 這兩者的影像分類模型。最後計數 count 則會記錄目前此類型的訓練資料有幾張。
這裡我們就分別對著鏡頭比讚,每點選一次「add」按鈕,就會將當前存檔成 jpg 檔。試著給予不同的角度與大小,並收集影像數量約達 40~50 張的照片即可。接下來在把類型切換到 thumbs_down,一樣拍攝 40~50 張照片,就可完成收集資料的部分。
2. 訓練模型
訓練模型其實只有一個參數要調整,就是訓練次數 epochs,建議可以設定 5~10 次就可以有不錯的效果,也不會花費太多的時間。點選「train」按鈕就會直接在 Jetson Nano 上跑模型訓練,依據資料量以及訓練次數 epochs 的不同,花費的時間也會有所差異。訓練過程同時也會看到進度條 progress bat、損失 loss、精確度 accuracy 的動態變化。理論上 loss 越小越好, accuracy 越趨近於一越好。
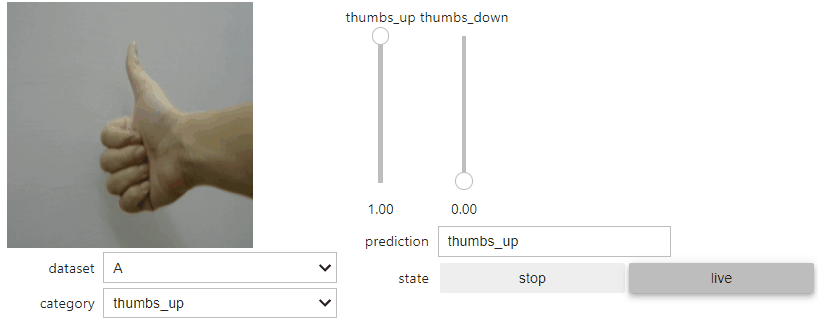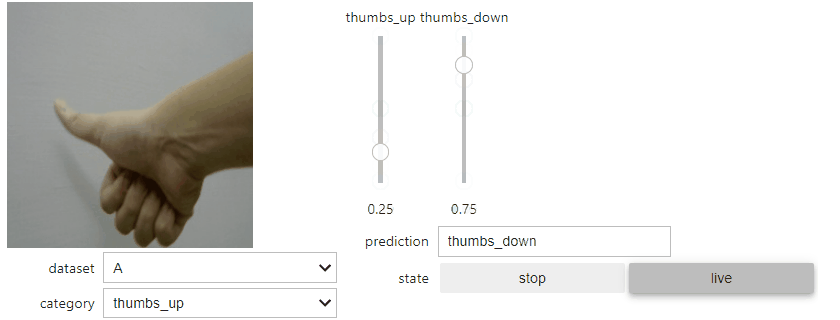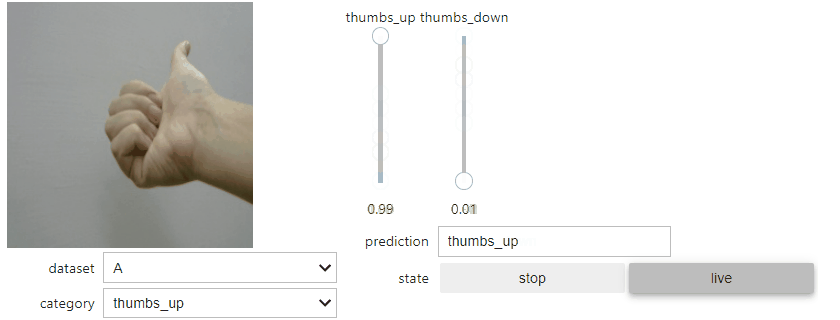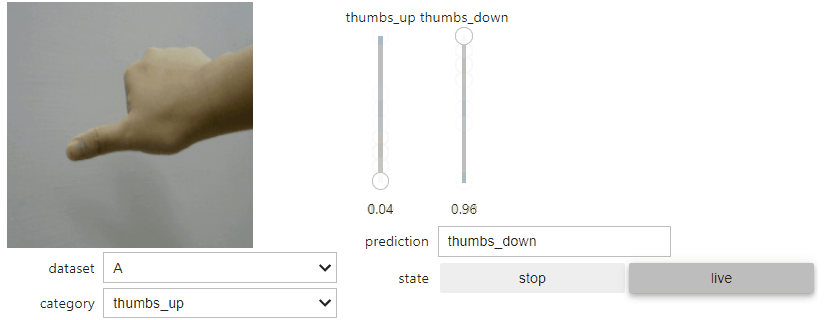
3. 測試
點選「live」按鈕後,會即時抓取如同預覽的 camera 影像資料,並且進行推論。推論判定的結果(模型判定的機率)以兩條滑動桿 Slider Bar 呈現,所有機率加總為 1 。筆者整體測試起來辨識度還相當不錯。
4. 儲存模型
若覺得當前的模型效果不錯,也可以從這裡點選「save model」按鈕,儲存後拿去其他裝置載入推論使用(認真( ͡° ͜ʖ ͡°))。儲存的格式為 Pytorch 使用的 pth 模型檔。不過記得要匯入模型的話,記得把類別的名稱數量改為和原模型一致,才不會發生問題。
三、遷移學習 Transfer Learning
各位可能會覺得好奇,為什麼訓練一個深度學習模型可以這麼快!?其實這範例用了叫做遷移學習 Transfer Learning 的技術,概念就跟人在學習新事物時會把舊有的經驗帶入,達到用較短時間學習新技術的效果。
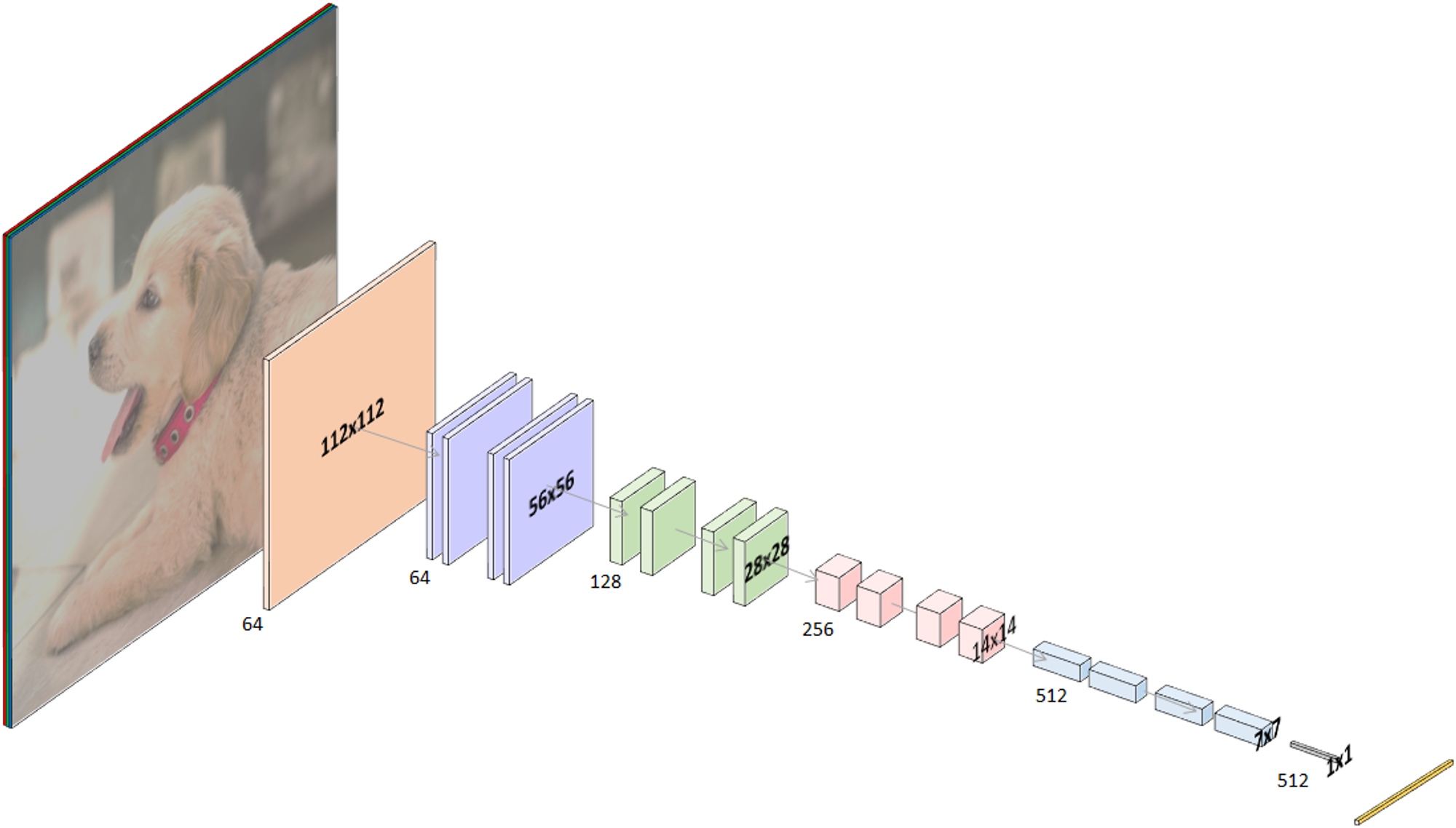
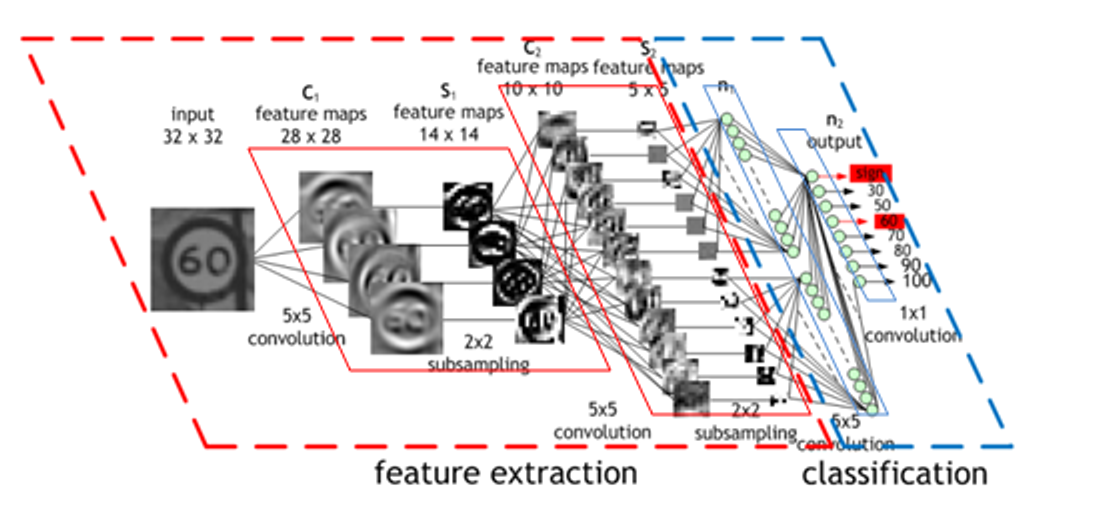
在卷積神經網路 (Convolutional Neural Networks, CNN) 中前半段的捲積 (Convolution) 與池化 (Pooling) 的運算,可以理解為是在萃取圖像中的特徵值。後段的全連接層 (fully connected layers) 來做各類特徵值對於不同類別的權重調整。因此前半段的神經網路權重可以直接拿其他人訓練好的模型來使用,而此範例中實際要訓練的權重就只有後段小部分的全連接的神經元了!
以此範例為例,使用的是 ResNet-18 神經網路架構,預訓練權重則是 LSVRC 2012 競賽使用的 ImageNet 影像分類資料集,涵蓋數以千計的分類與上百萬張的圖像資料。關於進一步 CNN 的細節這裡就不做贅述了,有興趣各位可以去 google 深度學習相關教學資源,都有許多高手的文獻可以學習。
四、設定任務 Task
回到此專案的前段程式碼,在 任務 Task 的程式碼 cell 可以看到 TASK, CATEGORIES, DATASETS 這三個參數的設定,分別就是對應到稍早使用的互動式工具上面的選項。預設使用的 thumbs 只有兩個分類,我們可以自行調整為其他範例的情緒分類或是手指數量分類,甚至要自行設定任務以及各個類別的名稱都是可以彈性調整的!DATASETS 指的是說此任務所收集的資料要分為幾個資料集,實際上只是把照片存在檔案系統時,用不同資料夾去儲存而已,方便將訓練資料歸檔整理。
TASK = 'thumbs'
# TASK = 'emotions'
# TASK = 'fingers'
# TASK = 'diy'
CATEGORIES = ['thumbs_up', 'thumbs_down']
# CATEGORIES = ['none', 'happy', 'sad', 'angry']
# CATEGORIES = ['1', '2', '3', '4', '5']
# CATEGORIES = [ 'diy_1', 'diy_2', 'diy_3']
DATASETS = ['A', 'B']
# DATASETS = ['A', 'B', 'C']五、模型設定 Model
模型設定的程式碼段落也有些可以調整的選項,程式碼註解部分延伸出除了預設的 ResNet-18 以外,其他三個模型可以做替換,分別為 AlexNet, SqueezeNet, ResNet-34,都算是輕量級參數量較小的 CNN 神經網路。這幾個神經網路在 pytorch 都有支援,選定好模型代入參數 pretrained=True,就可以直接載入預訓練好的權重。下面一行執行的 torch.nn.Linear 則是要讓原始模型輸出的全連接神經元 512 個線性對應到我們需要的分類數量。模型之間要替換只要用註解去調整,之後再重新執行此區塊以下的程式碼即可!
device = torch.device('cuda')
# ALEXNET
# model = torchvision.models.alexnet(pretrained=True)
# model.classifier[-1] = torch.nn.Linear(4096, len(dataset.categories))
# SQUEEZENET
# model = torchvision.models.squeezenet1_1(pretrained=True)
# model.classifier[1] = torch.nn.Conv2d(512, len(dataset.categories), kernel_size=1)
# model.num_classes = len(dataset.categories)
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, len(dataset.categories))
# RESNET 34
# model = torchvision.models.resnet34(pretrained=True)
# model.fc = torch.nn.Linear(512, len(dataset.categories))
model = model.to(device)六、小結
如果是初次體驗這次影像分類範例的夥伴,是否會覺得在邊緣裝置做 Edge AI 運算就如同玩 Teachable Machine 一樣簡單呢?~~(不這樣搞怎麼騙人入坑!(¬◡¬)✧)~~說實話 Edge AI 真的也是容易玩,不過彈性相當大,可淺也可深,而且也都會涵蓋到一些電子硬體的整合與知識量,這也是 Edge AI 有趣的地方啊!下一篇文章就讓我們繼續來看下一個範例囉!\(●´ϖ`●)/



