

想要了解更多有關 Duckietown 系列的操作文章,請參考以下文章 :
- Duckietown – Duckiebot DB21M 小鴨車專案 Jetson-Nano 版平台組裝與操作環境設定介紹
- Duckietown 專案 – Duckiebot DB21M 基礎操作(一)
- Duckietown 專案 – Duckiebot DB21M 基礎操作(二) – differential drive configuration的使用
- Duckietown 專案 – Duckiebot DB21M 基礎操作(三) – PID controller 的使用
- Duckietown 專案 – Duckiebot DB21M 基礎操作(四) – Camera Calibration 相機校正
一、前言
在上一篇文章 「Duckietown 專案 – Duckiebot DB21M 基礎操作(四) – Camera Calibrate」 中,我們將 Dcukiebot DB21M(以下簡稱小鴨車)的主要感測器 – 相機,使用相機本身校正與定向校正方法,找出相機的針孔成像模型相關參數。相機校正完成後,我們便可以開始使用相機作為主要感測器,去執行各種專案。本篇文章我們將探討最多人使用相機所做的專案 – 物件偵測(Object Detection)。
本篇文章我們將會分成以下三個部分,一步一步討論物件偵測所需要的基礎知識:
- 高階視覺感知簡介
- 物件偵測的探討
- 總結
二、高階視覺感知簡介
在上一篇文章中,我們操作了相機校正以找到參數,讓小鴨車在擷取影像資訊時,不至於與實際環境有過多的誤差出現,這部分使用到的是低階視覺感知技術。但有的時候,我們會需要從一張圖片中,推論更多有意義的物體,例如障礙物,這時就需要使用到「高階視覺感知技術(Advanced Visual Perception)」。對於小鴨車這種自動駕駛車來說,有意義的物體可能會是車子、行人、交通號誌道路標示等等,這些物體都包含了幾何形狀與語義的資訊。接下來,我們將定義一些不同的介紹三個高階視覺感知任務:影像分類、物件偵測與語義分割。
1. 影像分類(Image Classification )
在影像分類的任務中,我們將會給予系統一張圖片,其中包含了一個物體,隨後系統則會正確地辨識出影像中的物體是屬於哪個分類。例如我們給小鴨車一個鴨子的圖片,它可以正確地辨識出-鴨子。在辨識鴨子的任務中,小鴨車僅需要知道影像中的一個物體,並且不需要知道鴨子的位置,位在圖片中的哪個地方。然而這樣子單純的影像分類,並不適合用在自動駕駛車上,因為自動駕駛車還需要知道物體在圖片中的哪個方位,如下圖所示。

2. 物件偵測(Object Detection)
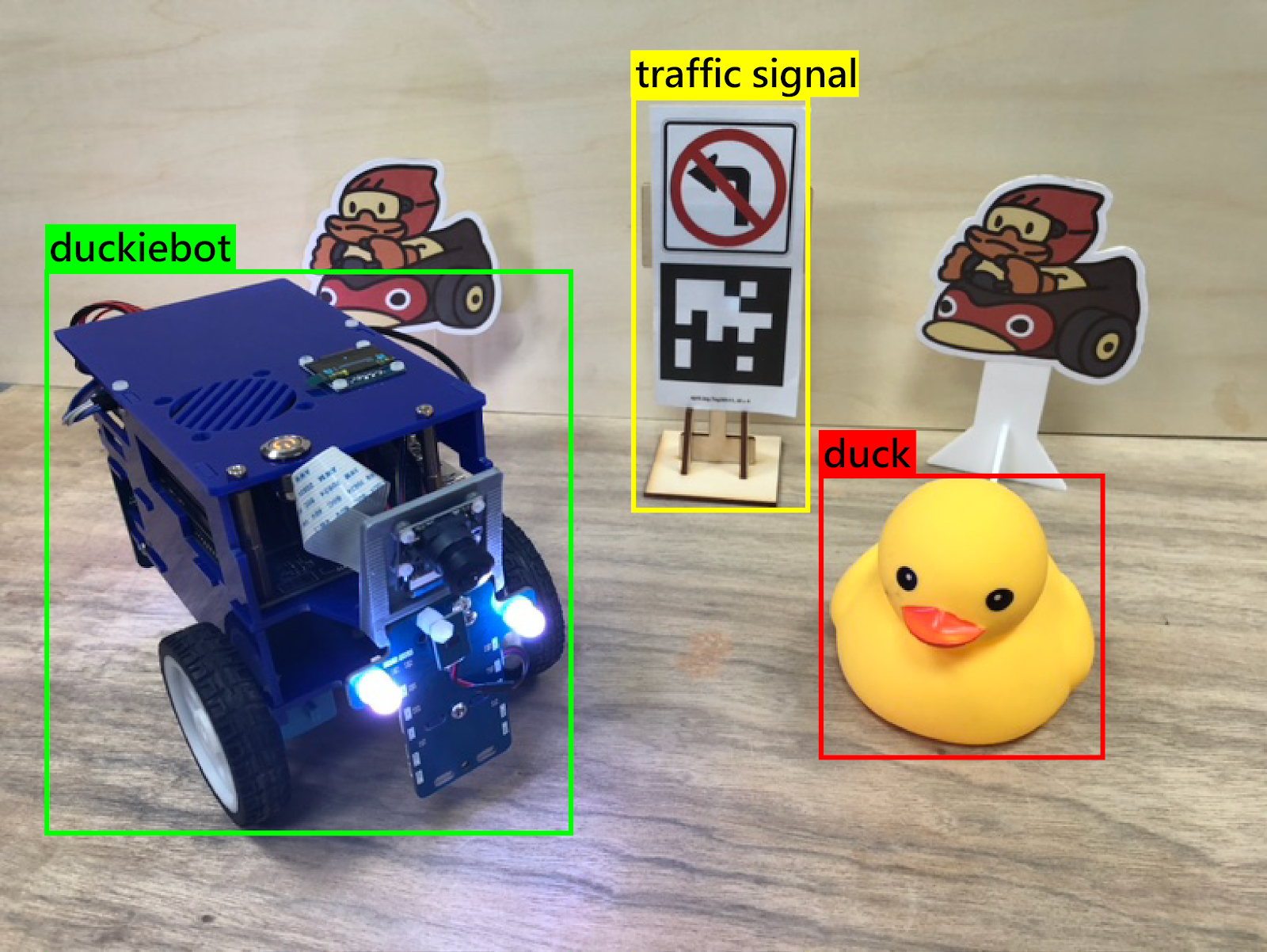
物件偵測是一個比影像分類還要困難的任務,原因在於同一個圖片中,可能會有多種不同的物體出現。在物件偵測任務中,我們需要知道圖片中出現的各種不同物體,並且以「邊界框(Bounding box, 或稱定界框)」來標示出物體在圖片中的方位。但這並不是影像分割,因為物件偵測不需要知道每個像素格所代表的精準分類。物件偵測不會去關注不是物體的區域,而是專注在提供一個完整的註釋給予被邊界框框定的物體,如下圖所示。
3. 語義分割(Semantic segmentation)
語義分割,也稱為圖像分割(Image segmentation),這項技術的的任務是找出圖片中每一個像素格(Pixel),所對應的標籤。舉個例子,在一張圖片,有很多隻的小鴨與交通號誌,這時我們就可以使用語義分割,將小鴨與交通號誌所佔有的像素格全部標示出來,這看起來就會像是把小鴨與交通號誌的輪廓畫出來,隨後再給予標籤,如下圖所示。

上述的影像分類、物件偵測、語義分割3個任務說明,是高階視覺感知中常使用的任務,接下來我們將把目標放在本篇文章的重點 – 物件偵測。
三、物件偵測的探討
在這裡我們馬上遇到第一個問題: 要如何評估物件偵測的效能呢?
若是在影像分類中,評估效能的方式相當簡單:辨識的準確度(Accuracy)越高,效能就越好。準確率的意思是在下列所有圖片中,能夠正確的辨識出Duckiebot 圖片類別的比率,化作公式即為:
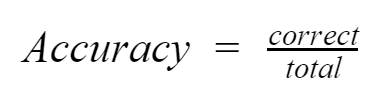

然而物件偵測並不能這麼直觀地探討效能,因為我們可能會檢測到一些不存在於辨識模型中的物體或是遺失一些應該辨識出的物體。為了探討物件偵測的效能,我們需要了解下列的基礎知識:
- 混淆矩陣(confusion matrix)
- 精確度(percision)
- 召回率(recall)
- 平均正確率
- mean Average Precision
- Intersection Over Union
1. 混淆矩陣(confusion matrix)
混淆矩陣是機器學習中,用來評估模型好壞的方法之一。假設現在我們有一個模型,需要用來判斷圖片中的物體,是否為一隻小鴨,則可能會有下列四種情況 :

- True Positives(TP) : 圖片中的物體為小鴨,模型預測也是小鴨
- True Negative(TN) : 圖片中的物體不是小鴨,模型預測也不是小鴨
- False Positives(FP) : 圖片中的物體不是小鴨,模型預測卻是小鴨
- Fasle Negative(FN) : 圖片中的物體是小鴨,模型預測卻不是小鴨
這四種情況如果使用表格來表示的話,便會是
| 模型預測是小鴨(Positives) | 模型預測不是小鴨(Negative) | |
| 給予的圖片是小鴨 | True Positives(TP) | Fasle Negative(FN) |
| 給予的圖片不是小鴨 | False Positives(FP) | True Negative(TN) |
透過表格我們便可以知道混淆矩陣所代表的意義:
- 模型預測的結果是正相關、正面肯定語句的,即可以「Positives」表示,反之則以 「Negative」表示。
- 若模型預測的結果,與真實情況相同,則可以 「True」表示,反之則以「False」表示。
當有了混淆矩陣之後,我們便可使用精確度(percision)與召回率(recall),來進一步評估物件偵測的效能。
2. 精確度(percision)

我們來看一下上圖中辨識出「duckie」的標籤。精確度的計算公式如下:
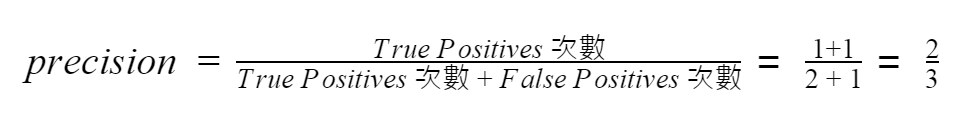
由上述的公式可以知道精確度指的是在被邊界框框起物體的基準上,給定正確標籤的比例。
3. 召回率(recall)

接著我們來看如何計算上圖中的召回率:
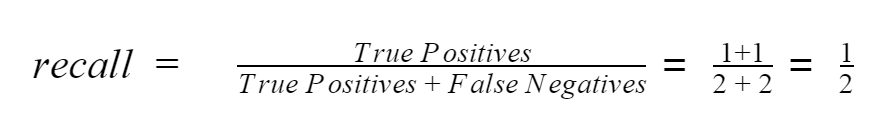
與精確度不同的地方在於,召回率還需要考慮到未被邊界框框起並標示的欲辨識物體(紅框處)。因此在計算上,需要將畫面中所有的欲辨識物體也考慮在內。
4. 平均正確率(average precision)
在計算出精確度與召回率後,我們便可以想盡辦法,讓精確度與召回率皆為 1 ,代表物件偵測的效能是最佳的狀態。通常我們可以使用一些參數來改變精確度與召回率,像是調整信心閥值(confidence threshold),讓物件偵測可以找出更多在畫面上的物體以便提高召回率,但同時也會有降低精確度的可能性。
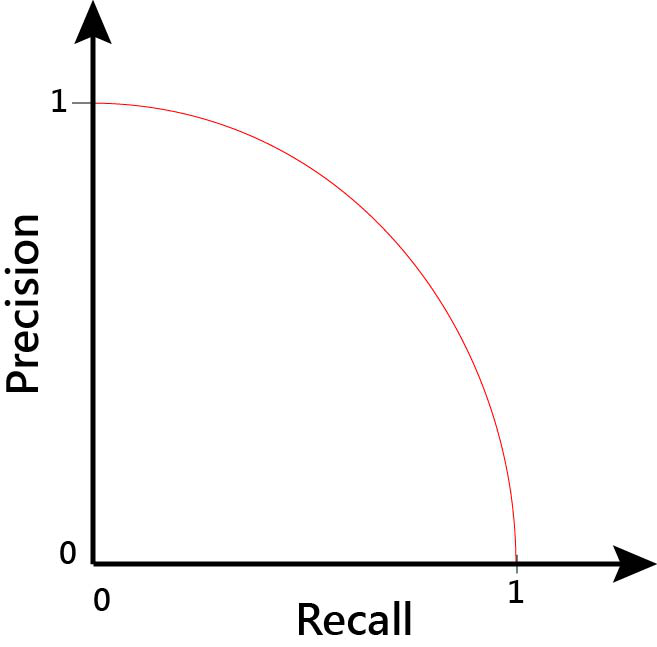
透過調整信心閥值,我們將可以得到精確度與召回率的關係式 Percision Recall,或稱為 PR曲線(PR curve),如上圖所示。
PR曲線在初始時會從左上邊開始,當物件偵測在圖像中,任何物體都沒檢測到時,精確度為 1;當檢測到所有物體時 ,召回率為 1。因此,在偵測到所有物體並且所有物體皆標示正確的情況下,PR曲線下的面積,平均正確率(average precision),將會是最大值。
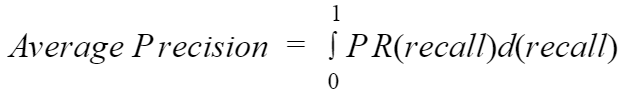
然而平均正確率我們很難去計算,因此我們可以透過在一定的區間內,在召回率的基準點上,獲得的精確度進行採樣,取得平均值。
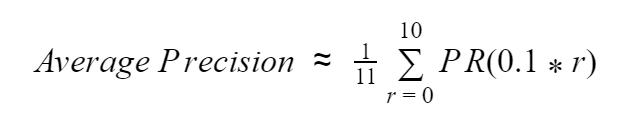
5. mean Average Precision ( mAP )
然而在物件偵測中,我們偵測到的物體並不會只有一個。因此,我們需要對所有檢測到的物體,進行平均正確率的計算,之後再將每個偵測物體的平均正確率再取平均值,這就是「mean Average Precision」也是我們用來確認物件偵測效能的指標之一。
6. Intersection Over Union
物件偵測效能的另一個指標,是邊界框框定物體的準確度。為了評估這一個準確度,我們使用 Intersection Over Union(以下簡稱IOU),這是用來計算預測的邊界框與實際上邊界框的比例,如下圖所示。

以上方的圖片為例子,紅框是物件偵測模型預測的邊界框,綠框則是實際上物體的邊界框。IOU 即是計算紅框與綠框的交集處與紅框與綠框的聯集處比例。從上圖的表現來看,當 IOU 計算後的數值為 1 時,代表物件偵測對於邊界框的處理上是完美的。
四、總結
通常我們在談論物件偵測的效能時,會使用下列的術語作為報告:
「這個物件偵測的效能,在 IOU的閥值為 0.8 時,mAP的數值為 0.6」
透過這樣子的說明,我們便能大概理解該物件偵測器的效能。
物件偵測是一個很重要的視覺感知任務之一,並且在自動駕駛車上,可以說是一個必要的感知任務。下一篇文章,我們將會向大家說明現代的物件偵測系統是如何運作的,請各位多多關注與分享我們的文章喔!



